
PostgreSQLからSnowflakeへ 移行の検討 -データ移行-
PostgreSQLからSnowflakeへの移行方法を検討したため、備忘録を兼ねて検討した内容とやったことを書きたいと思います。
「テーブル定義の移行」と「データ移行」を前編と後編に分けて掲載します。
本記事は後編「データ移行」となります。
目次
- はじめに
- PostgreSQLからのデータ出力
- COPY TOコマンド
- 単一のテーブル指定によるデータ出力
- SELECTクエリによるデータ出力
- ステージへのファイルアップロード
- ファイルのデータロード
- 名前付きファイル形式の作成
- COPY INTOコマンド
- クエリを使用したCOPY INTOコマンド
- データロードの実行
- ロードしたデータの確認
- まとめ
1. はじめに
当記事は前回の記事の後編となります
⇒ PostgreSQLからSnowflakeへ 移行の検討 -テーブル定義の移行-
Snowflakeについての説明や、移行を検討した理由については前編に記載していますのでそちらをご覧ください。
PostgreSQLからSnowflakeへデータを移行する方法としては以下の2つがあります。
①SnowflakeのサードパーティーETLツールを使用する
②移行データをファイル出力してSnowflakeへロードする
今回は「②移行データをファイル出力してSnowflakeへロードする」の方法でデータ移行を検討しました。
2. PostgreSQLからのデータ出力
PostgreSQLのデータをファイル出力する一般的な方法として「COPY TOコマンド」があります。
今回はCOPY TOコマンドを使用してCSVファイルへのデータ出力をしました。
COPY TOコマンド
COPY TOコマンドの構文は以下の通りです。
COPY table or sql_query TO out_file_name WITH options
パラメータの説明
table or sql_query:データ移行をしたい単一のテーブル、またはSELECTクエリを指定します
out_file_name:出力ファイルのパスを指定します
options:出力設定を指定します
参考)COPY (postgresql.jp)
単一のテーブル指定によるデータ出力
対象のテーブルを指定するだけで、そのテーブルの全データのデータ出力ができます。
ただし、単一のテーブルを指定した場合は出力時のデータのフォーマット形式は指定できません。
フォーマットの指定が必要な場合は次に説明する「SELECTクエリによるデータ出力」の方法でデータ出力をしましょう。
例)「sales」テーブルの全レコードをCSVファイルとして出力したい。
出力先のファイルは「C:\sales_202312.csv」、ヘッダー付きで、項目はカンマ区切り(,)、項目は二重引用符(")で囲みたい。
COPY sales TO 'C:\sales_202312.csv' WITH CSV FORCE QUOTE * HEADER ;
上記のコマンドでデータが出力できます。
※出力方法にCSVを指定した場合、デフォルトはカンマ区切りとなります。また、NULLの場合は空文字となります。
SELECTクエリによるデータ出力
データを特定のフォーマット形式で出力したい場合や、複数テーブルを結合した結果を出力したい場合は、COPY TOコマンドにSELECTクエリを指定します。
例)「sales」テーブルの全レコードをCSVファイルとして出力したい。
列「slip_number」は数値に変換し、列「sales_date」はタイムゾーン部分を「+(-)hh:mm」形式で出力したい(タイムゾーンはデフォルトでは「+(-)hh」形式で出力される)
出力先のファイルは「C:\sales_202312.csv」、ヘッダー付きで、項目はカンマ区切り(,)、項目は二重引用符(")で囲みたい。
COPY (
SELECT
slip_number::numeric
, to_char( sales_date, 'YYYY-MM-DD HH24:MI:SS.MSTZH:TZM' )
, sales_code
, product_code
, amount
FROM sales
)
TO 'C:\sales_202312.csv' WITH CSV FORCE QUOTE * HEADER ;
上記のコマンドでデータが出力できます。
3. ステージへのファイルアップロード
Snowflakeへファイルのデータをロードする場合、Snowflakeとファイルのやりとりをするための保管場所、「ステージ」が必要となります。
「ステージ」へファイルをアップロードすることで、そのファイルをSnowflakeへロードできます。
ステージには「外部ステージ」と「内部ステージ」がありますが、
ローカルPCから直接Snowflakeとファイルのやり取りをするのであれば、「内部ステージ」
外部ストレージ経由(AmazonS3)でSnowflakeとファイルのやり取りをするのであれば、「外部ステージ」
が必要となります。
今回は「外部ステージ」にファイルをアップロードし、そのファイルのデータをロードする方法で進めました。
「内部ステージ」でもデータロードの作業はできるため、やりやすい方法で進めるといいです。
別の記事でステージの準備方法、およびステージへのファイルアップロード方法について説明しているので、ファイルアップロードの方法がわからない方は以下の各記事を参考に進めてみてください。
・内部ステージ ⇒ 【Snowflake】ローカルファイルのデータをロードする
・外部ステージ ⇒ 【Snowflake】AmazonS3上のファイルのデータをロードする
ステージへのファイルのアップロードが完了したら、実際にファイルのデータをロードしていきます。
4. ファイルのデータロード
Snowsight(Snowflakeウェブインターフェイス)でファイルのデータをロードしていきます。
名前付きファイル形式の作成
Snowflakeへデータのロードするためには「COPY INTO」コマンド(SQL)を実行します。
COPY INTOコマンドでファイルをロードする際に、事前に作成したファイル形式の設定「名前付きファイル形式」を使用することができます。
「名前付きファイル形式」を使用すれば、コマンドで毎回細かくファイル形式を指定する必要がありません。
前段の章でPostgreSQLからデータ出力したファイルが「ヘッダー付きで、項目はカンマ区切り(,)、項目は二重引用符(")で囲まれたCSVファイル」となっています。
このファイルをロードするため、以下の設定の名前付きファイル形式を作成します。
■名前付きファイル形式の設定
・ファイル形式:CSV
・ヘッダー:最初の行をスキップ
・オプションで囲まれたフィールド:二重引用符
名前付きファイル形式をSnowflakeに作成するため、「CREATE FILE FORMAT」コマンド(SQL)をSnowsightのワークシートで実行します。
CREATE OR REPLACE FILE FORMAT fileformat_CSV
TYPE = CSV
SKIP_HEADER = 1
FIELD_OPTIONALLY_ENCLOSED_BY='"'
今回は「fileformat_CSV」という名前を付けました。名前は管理しやすいように自由に命名してください。
なお、「CREATE FILE FORMAT」コマンドは様々なパラメータが用意されているので、ロードしたいファイルの形式によってパラメータは変更してください。
コマンドの詳細は、以下のリンク先(公式ドキュメント)を参考にしてください。
参考)データロードの準備 | Snowflake Documentation
CREATE FILE FORMAT | Snowflake Documentation
COPY INTOコマンド
Snowflakeへデータのロードするためには「COPY INTO」コマンド(SQL)を実行します。
COPY INTOコマンドの基本構文は以下の通りです。
COPY INTO table
FROM @stage
[ FILES = ( 'file_name' ) ]
[ PATTERN = 'regex_pattern' ]
[ FILE_FORMAT = ( { FORMAT_NAME = 'file_format_name' } ) ]
パラメータの説明
table:データ移行先となるテーブルを指定します
stage:ロードをするファイルがアップロードされているステージを指定します
file_name:ファイル名を指定してロードする場合、オプションパラメータ「FILES」を使用してファイル名を指定します
regex_pattern:正規表現パターンでファイル名を指定してロードする場合、オプションパラメータ「PATTERN」を使用して正規表現パターンを指定します
file_format_name:事前に作成した名前付きファイル形式を指定してロードする場合、オプションパラメータ「FILE_FORMAT」の「FORMAT_NAME」でファイル形式名を指定します(ステージ自体にファイル形式を設定している場合はパラメータは不要です)
※「FILE_FORMAT」については、名前付きファイル形式を使用せず、コマンドでファイル形式を指定する方法もあります
コマンドで指定したい場合は、以下のリンク先(公式ドキュメント)を参考にしてください
参考)S3ステージからのデータのコピー | Snowflake Documentation
COPY INTO <テーブル> | Snowflake Documentation
クエリを使用したCOPY INTOコマンド
基本構文ではCOPY INTOの先を「table」とし、FROM句では単純にファイルを指定する方法が書かれていますが、SQLのINSERT INTOと似たような書き方で「ファイルからクエリでデータ取得⇒移行先のテーブルへデータロード」も可能です。
データロードの際にデータの形式をフォーマットしたい場合は、クエリを使用してCOPY INTOコマンドを実行することになります。※日付や時刻のデータがある場合はこちらも参考にしてください
また、ファイルのデータをロードするだけでなく、ファイルの情報(メタデータ)をSnowflakeのテーブルに登録することもできます。
メタデータも一緒にテーブルに保持しておきたい場合は、データ移行先のテーブルにメタデータ登録用のカラムを用意しておきましょう。
ファイルには以下のメタデータが生成されています。
※使い方はこちらでサンプルを書きました
| メタデータ列 | 説明 | 備考 |
|---|---|---|
| METADATA$FILENAME | ステージでのファイルへのパスとファイル名 | |
| METADATA$FILE_ROW_NUMBER | 対象データのファイル内の行番号 | |
| METADATA$FILE_CONTENT_KEY | ファイルのチェックサム | |
| METADATA$FILE_LAST_MODIFIED | ファイルの最終更新タイムスタンプ | TIMESTAMP_NTZ |
| METADATA$START_SCAN_TIME | 対象データのロード開始タイムスタンプ | TIMESTAMP_LTZ |
参考)ステージングされたファイルのメタデータのクエリ | Snowflake Documentation
ファイルからデータを取得するクエリの基本構文は以下の通りです。
SELECT [ alias ].$file_col_num1 [ , [ alias ].$file_col_num2, [ alias ].$file_col_num3, … ]
FROM @stage
[ ( FILE_FORMAT => 'file_format_name', PATTERN => 'regex_pattern' ) ]
[ alias ]
パラメータの説明
alias :FROM句で定義されているオプションのテーブルエイリアスを指定します(定義している場合)
file_col_num:ファイルから取得したい列番号を指定します 複数列のデータを取得したい場合はカンマ区切りで指定します
stage:ファイルがアップロードされているステージを指定します
file_format_name:オプションパラメータ「FILE_FORMAT」の「FORMAT_NAME」で名前付きファイル形式名を指定します
regex_pattern:正規表現パターンでファイル名を指定してロードする場合、オプションパラメータ「PATTERN」を使用して正規表現パターンを指定します
参考)ステージングされたファイルのデータのクエリ | Snowflake Documentation
基本構文のSELECT句部分で、必要に応じて形式のフォーマットをすることができます。
また、形式フォーマット以外にもデータ型の変換や置換、CASEによる分岐の関数なども用意されているため、基本的なSQLの処理はできると思ってよさそうです。
何ができるかは公式のリファレンスを参照すると良いでしょう。
参考)SQL コマンドリファレンス | Snowflake Documentation
SQL 関数リファレンス | Snowflake Documentation
以下はクエリで取得したデータを、移行先のテーブルへロードする構文です。
COPY INTO table ( column1 [ , column2, column3, … ] )
FROM (
SELECT [ alias ].$file_col_num1 [ , [ alias ].$file_col_num2, [ alias ].$file_col_num3, … ]
FROM @stage
[ ( FILE_FORMAT => 'file_format_name', PATTERN => 'regex_pattern' ) ]
[ alias ]
)
前段で説明したファイルからデータを取得するクエリを、COPY INTOコマンドのFROM句にサブクエリとして記入します。
メタデータをテーブルへ登録したい場合は、サブクエリのSELECT句にメタデータ列を追加します。
次に説明するデータロードの実行で実行サンプルを紹介しているので、そちらも参考にしてください。
★Snowflakeでロードできる日付、時刻の形式について
当検証作業でSnowflakeへロードする際に一部の日付・時刻データが省略された状態でロードされるという事象が発生しました。
Snowflakeのデータロードは日付、時刻、およびタイムスタンプの入力文字列について、特定の形式をSnowflakeが自動的に検出するか、ロードするデータの形式をSnowflakeが定めている形式の要素で指定することでそれぞれロードができる仕組みになっています。
そのため、Snowflakeへロードする際に前述の「クエリを使用したCOPY INTOコマンド」を使用し、形式の変換をしてロードをすることで解決しました。
例)時刻のナノ秒部分がSnowflakeにロードされない データ(CSV列番号=1):2024/02/14 10:00:00.123456+09
⇒ クエリのSELECT句で変換関数を使用する ※タイムスタンプの場合は変換関数「TO_TIMESTAMP_LTZ」を使用
ナノ秒部分は「FF」、タイムゾーン(+(-)hh)部分は「TZH」で表す
COPY INTO SALES ( sales_date)
FROM (
SELECT TO_TIMESTAMP_LTZ( t.$1 , 'YYYY-MM-DD hh24:mi:ss.FFTZH')
FROM @MY_S3_STAGE_BLUE
( FILE_FORMAT => 'fileformat_CSV', PATTERN => '.*sales.*.csv' )
t
)
参考)日付および時刻の入力/出力 | Snowflake Documentation
変換関数 | Snowflake Documentation
データロードの実行
準備ができたので、COPY INTOコマンドを実行してデータをロードしていきます。
Snowsightのワークシートを開き、用意したCOPY INTOコマンドをワークシートに記入して実行します。
※ワークシートのデータベースとスキーマはデータのロード先を指定しておきましょう
エラーとなった場合は、エラーメッセージを読んでSQLを修正します。(構文誤り、記号が半角ではなく全角になっている、カンマが抜けている 等がよくあるケースです)
★ファイル内のデータとメタデータをSnowflakeのテーブルへロードするサンプル
ステージ「MY_S3_STAGE_BLUE」にアップロードされている「sales」が名前についているファイルを、テーブル「MIGRATION_SALES」へデータロードする。
■ステージ「MY_S3_STAGE_BLUE」にアップロードされている「sales_202312.csv」ファイルの中身
"slip_number","sales_date","sales_code","product_code","amount"
"100005","2023-12-01","100001","0053","1000"
"100006","2023-12-01","100002","0060","800"
"100007","2023-12-02","100001","0061","900"
"100008","2023-12-03","100003","1050","4000"
■テーブル「MIGRATION_SALES」のテーブル定義 (DB名「TRAINING_DB」、スキーマ名「PUBLIC」)
CREATE OR REPLACE TABLE TRAINING_DB.PUBLIC.MIGRATION_SALES (
SLIP_NUMBER VARCHAR(6),
SALES_DATE DATE,
SALES_CODE VARCHAR(6),
PRODUCT_CODE VARCHAR(4),
AMOUNT NUMBER(38,0),
FILENAME VARCHAR(16777216),
FILE_ROW_NUMBER NUMBER(38,0)
)
ロード時に、列「FILENAME」にロードファイルのファイル名(バケットからのパス)、列「FILE_ROW_NUMBER」にデータの行番号を登録する。
上記のテーブル「MIGRATION_SALES」へデータをロードする場合のCOPY INTOコマンド↓
COPY INTO MIGRATION_SALES ( slip_number, sales_date, sales_code, product_code, amount, filename, file_row_number)
FROM (
SELECT
t .$1, t.$2, t.$3, t.$4, t.$5
, METADATA$FILENAME
, METADATA$FILE_ROW_NUMBER
FROM @MY_S3_STAGE_BLUE
( FILE_FORMAT => 'fileformat_CSV', PATTERN => '.*sales.*.csv' )
t
)
※前段の手順で説明したファイル形式「fileformat_CSV」を使用しています
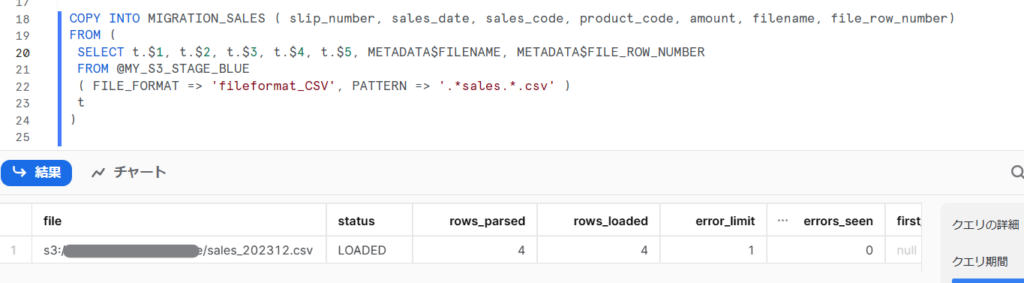
ロードできました。
ロードしたデータの確認
ロードしたデータの確認は、Snowsightのデータベースメニューから対象のテーブルを開き、データプレビューを表示するか、ワークシートでSQL(SELECT文)を実行します。
例)「MIGRATION_SALES」テーブルにロードされたデータを確認します。
Snowsightのワークシートを開き、データベースとスキーマを選択し、下記SQLを実行する。
SELECT * FROM MIGRATION_SALES ;
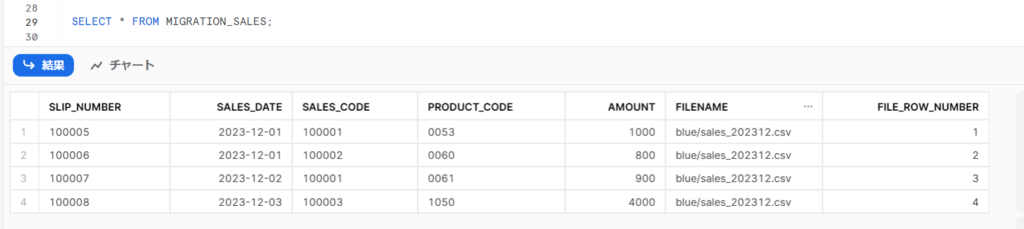
こちらでロードしたサンプルデータが確認できました。
列「FILENAME」にロードファイルのファイル名、列「FILE_ROW_NUMBER」にデータの行番号が登録されています。
5. まとめ
本記事では、PostgreSQL からSnowflakeへのデータの移行について検討した内容をまとめました。
前編で説明したテーブル定義の移行ができればそこまで大変な作業ではなかったかと思います。
日付・時刻型のデータについては、Snowflakeへロード可能な形にする工夫が必要かもしれないため注意したほうがよさそうです。
移行するテーブルが多い場合は、CreateTableのDDLやCOPY INTOコマンドを作成する作業に時間がかかると思います。
まずは少量のデータでデータロードまでの検証をし、問題なくロードされたことを確認したら実際のデータをロードするといいでしょう。

