
連続データパイプラインを作ってみる
連続データパイプラインの作成方法をご紹介します。
以下のような方にお勧めとなります。
- 継続してファイルの内容を取り込みたい
- ファイル読み込みの監視は行いたくない
- ウェアハウスの管理、変化する処理量にあわせたスケーリングなどはSnowflakeに任せたい
目次
- 連続データパイプラインとは?
- 外部ステージの準備
- Snowpipeの作り方
①準備
②Snowpipe作成
③権限の設定
④イベント通知設定 - ストリームの作り方
- タスクの作り方
①取込先のテーブルを準備
②タスクを作成
③タスクの実行権限を付与
④タスクの起動 - データパイプラインを試してみる
- 後処理
- まとめ
1.連続データパイプラインとは?
データパイプラインは、連続的なデータロードに伴う多くの手順を自動化します。
多くの場合、生データはテーブルに一時的にロードされ、その後にSQLによって変換されて保存先テーブルに挿入されます。
この流れをsnowflakeの以下機能を組み合わせて作成することができます。
①連続データロードの機能
- Snowpipe
- Snowpipe Streaming
- Kafka用のSnowflakeコネクタ
- サードパーティのデータ統合ツール
②連続データパイプ
③変更データの追跡
④定期的なタスク
・タスク
今回は①Snowpipe + ③ストリーム + ④タスク を使用して以下のデータパイプラインを作成します。

2.外部ステージの準備
まずは外部ステージを作成します。
作成する外部ステージは、AWSのS3バケット上の特定のフォルダを参照するため、S3バケットに対するデータの読み書き権限が必要になります。
snowflakeのストレージ統合オブジェクトを使うことで、S3バケットに対する読込を許可するIAMロールの権限を取得できます。
ストレージ統合オブジェクト、ストレージ統合を参照する外部ステージは、以下のドキュメントを参考に作成してしてください。
以降の手順では、作成した外部ステージ「MY_S3_STAGE_GREEN」を使用します。
3.Snowpipeの作り方
Snowpipeを使用するとファイルがステージで利用可能になったことを検知して、ファイルからデータを継続的にロードできます。
①準備
今回ロードするファイルは、以下のようなJSON形式のデータを使用します。
{"sales_date":"20231101","product_code":"F001","quantity":1}
{"sales_date":"20231101","product_code":"F002","quantity":2}
{"sales_date":"20231101","product_code":"V001","quantity":1}
Snowpipeがデータをロードする先のテーブルを作成します。
以下のCREATE文を実行して、JSON形式のデータを格納するためのVARIANT型のカラムだけを持つテーブルを作成します。
create or replace table blog_green.for_blog.raw (
record variant
);
②Snowpipe作成
今回はAWSの「S3イベント通知」をトリガーとして、データをロードするようにします。
auto_ingest = true と指定することで、メッセージサービスからイベント通知を受信したときに、指定した外部ステージからデータファイルを自動的にロードします。
create or replace pipe blog_green.for_blog.pipe_sales auto_ingest=true as
copy into blog_green.for_blog.raw
from @blog_green.for_blog.my_s3_stage_green
file_format = (type = 'JSON');
③権限の設定
Snowpipeを使用するには、次の権限を持つロールが必要となります。
| オブジェクト | 権限 |
|---|---|
| 名前付きパイプ | OWNERSHIP |
| 名前付きステージ | USAGE , READ |
| 名前付きファイル形式 | USAGE |
| ターゲットデータベース | USAGE |
| ターゲットスキーマ | USAGE |
| ターゲットテーブル | INSERT , SELECT |
※名前付きファイル形式は作成した外部ステージが名前付きファイル形式を参照する場合にのみ必要です。
今回は使用しないため、権限の確認は行いません。
今回はユーザ「SNOWPIPE_USER」に権限を設定します。
※「最小権限」の原則に従うためパイプを使用する個別のユーザとロールを作成することが推奨されています。
-- ロール作成
create or replace role snowpipe1;
-- データベースオブジェクトに必要な権限をロールに付与
grant usage on database blog_green to role snowpipe1;
grant usage on schema blog_green.for_blog to role snowpipe1;
grant insert, select on blog_green.for_blog.raw to role snowpipe1;
grant usage on stage blog_green.for_blog.my_s3_stage_green to role snowpipe1;
-- パイプオブジェクトにOWNERSHIP権限を付与
grant ownership on pipe blog_green.for_blog.pipe_sales to role snowpipe1;
-- ユーザにロールを付与
grant role snowpipe1 to user snowpipe_user;
alter user snowpipe_user set default_role = snowpipe1;
設定した権限を確認します。
show grants to role snowpipe1;
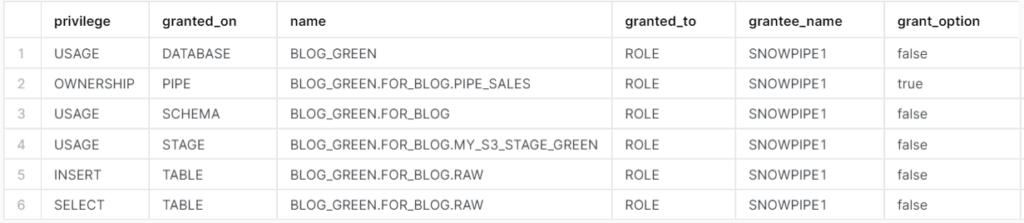
必要な権限が付与されていることが確認できました。
④イベント通知設定
AWSのS3バケットのイベント通知を構成して、新しいデータをロードできるようになったときにSnowpipeに通知します。
ARNを取得
SHOW PIPES コマンドを実行します。
show pipes;
取得結果

notification_channel 列にあるSQS キューの ARN をコピーします。
S3バケットのイベント通知を構成
Amazon S3コンソールにログインします。
Amazon S3ドキュメント に記載されている手順を使用して、S3バケットのイベント通知を構成します。
AWSの管理コンソールから、外部ステージとして使用するS3バケットの画面を開き
「プロパティ」タブの「イベント通知を作成」を選択します。
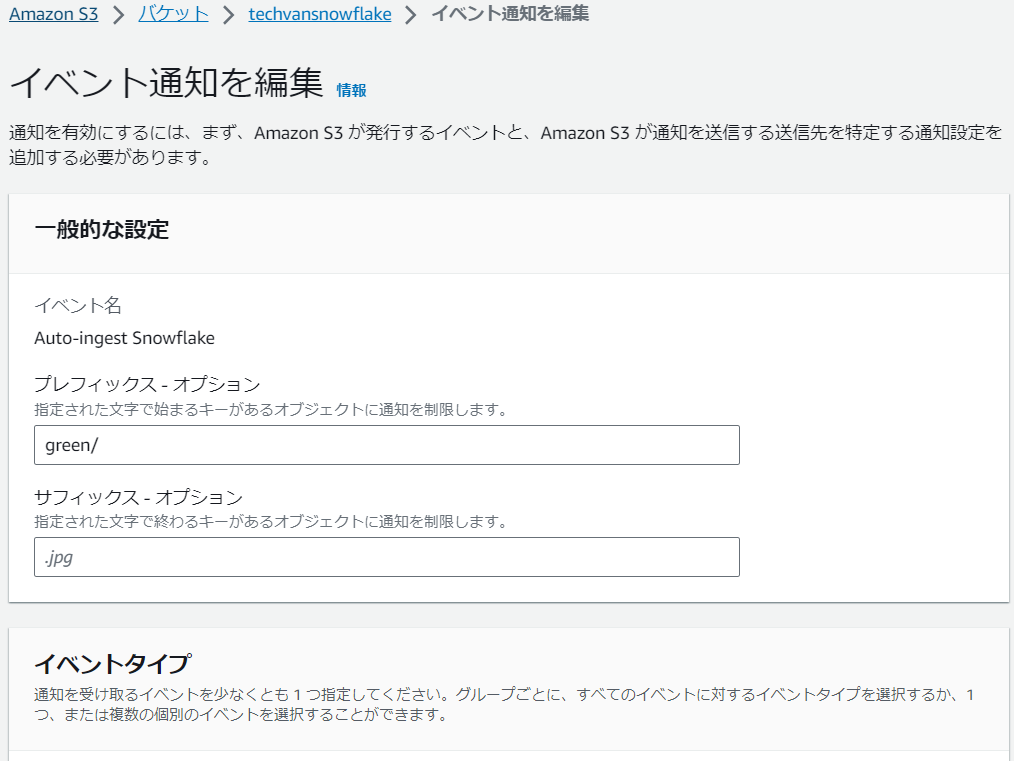
- イベント名:任意の名前を入力します。
- イベント:「すべてのオブジェクト作成イベント」を選択します。
- プレフィックス:外部ステージの配下にある特定のフォルダ内のファイルをロードしたい場合は指定します。
- 送信先:「SQS キュー」を選択します。
- SQS キュー を特定:「SQS キュー ARN を入力」を選択し、先ほど notification_channel 列から取得したSQS キューのARNを入力します。
上記を選択/入力したら「変更の保存」をします。
4.ストリームの作り方
ストリームはテーブルに加えられた変更(挿入、更新、削除など)を追跡できるオブジェクトです。
変更および変更に関するメタデータを記録し、変更されたデータを使用してアクションを実行できるようにします。
この機能を利用して、外部ステージからデータをロードするテーブル「Raw」のレコードに対する差分を検出するストリームを作成します。
create or replace stream blog_green.for_blog.raw_stream on table blog_green.for_blog.raw;
5.タスクの作り方
タスクは以下のいずれかを実行できます。
- 単一の SQL ステートメント
- ストアドプロシージャへの呼び出し
- Snowflakeスクリプトを使用した手続き型ロジック
今回は定期実行する単純なタスクを作成します。
タスクの実行がスケジュールされるたびに、ストリームにテーブルの変更データが含まれているかどうかを確認し、
変更データを消費するか、変更データが存在しない場合は現在の実行をスキップします。
「JSON形式のデータをテーブル「Raw」からストリームを利用して読み込み、各カラムに分割してテーブル「Sales」に取り込む」という処理のタスクを作成します。
①取込先のテーブルを準備
create or replace table blog_green.for_blog.sales (
sales_date varchar(8),
product_code varchar(10),
quantity number(5,0)
);
②タスクを作成
create or replace task blog_green.for_blog.raw_task
warehouse=blog_wh
schedule='1 minute'
when
system$stream_has_data('raw_stream')
as
insert into sales
select
record::sales_date::varchar as sales_date,
record::product_code::varchar as product_code,
record::quantity::number as quantity
from
raw_stream;
③タスクの実行権限を付与
タスクの起動には「グローバル権限」の「EXECUTE TASK」が必要なため、ACCOUNTADMINでロール「snowpipe1」に権限を付与します。
タスクの所有者ロール「SYSADMIN」がタスクを実行できるように「snowpipe1」を割り当てます。
grant execute task on account to role snowpipe1;
grant role snowpipe1 to role sysadmin;
④タスクの起動
新しく作成したタスクは「一時停止済み」の状態のため、タスクを起動します。
alter task raw_task resume;
6.データパイプラインを試してみる
実行前のテーブルを確認します。
※SELECTは、テーブルを作成したロール「SYSADMIN」で実施します。
ロール「snowpipe1」はテーブル「raw」のSELECT権限は付与されていますが、「sales」の権限は付与されていないためです。
select count(*) cnt from blog_green.for_blog.raw;

select count(*) cnt from blog_green.for_blog.sales;
S3にファイルを配置します。

テーブルを確認します。
select * from blog_green.for_blog.raw;

テーブル「raw」にレコードが3件登録されました。
select * from blog_green.for_blog.sales;

テーブル「sales」に指定した通りカラムが分割された状態で3件登録されました。
7.後処理
タスクが動き続けてしまうため、停止します。
alter task raw_task suspend;
8.まとめ
今回はJSON形式のデータをロードしましたが、Snowpipeは半構造化データ型を含む全てのデータ型がサポートされています。
また、複数のタスクを実行したりストアドプロシージャを呼び出すなどもできるため、要望に合ったデータ変換を試してみてください。
